Немного про сжатие данных
Алгоритм Хаффмана - самый простой и понятный алгоритм сжатия данных.
Представим, что у нас есть строка:
aaaaebbbaccaddae
Для того, чтобы сжать эту строку без потерь, нам нужно каждому символу присвоить некий код. Но делать мы это будем не просто так, а начнем с самого частого символа, то есть с a, и будем следовать 2м простым правилам:
- Код должен быть короче для тех символов, которые встречаются чаще;
- Код должен однозначно декодироваться, т.е. иметь уникальный префикс (т.е. нельзя выдать коды 0, 01, 10, т.к. в таком случае 00110010 может трактоваться по-разному).
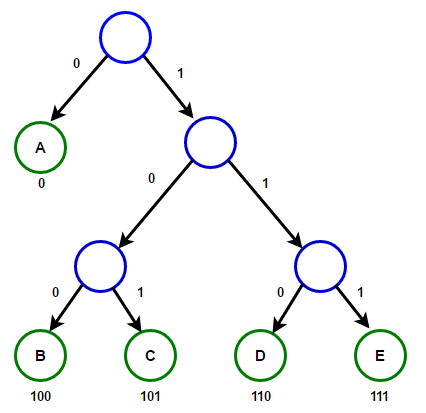
Получится что-то типа такого:
a - 0
b - 100
c - 101
d - 110
e - 111
Теперь мы можем однозначно кодировать и декодировать строку:
0|0|0|0|111|100|100|100|0|101|101|0|110|110|0|111
Это алгоритм базового кодирования переменной длины.
А теперь что же предлагает нам алгоритм Хаффмана?
Предлагает построить нам бинарное дерево, где слева будут ноды с "0", а справа - с "1".
Принцип построение будет следующий:
- Создаем ноды для каждого символа и положим их в очередь;
- Пока в очереди больше одного элемента, делаем так:
- Удаляем два узла, символы которых встречаются реже всего;
- Создаем новую ноду, добавляем ее в очередь, а эти две помещаем чилдами, а частоту складываем. - Если осталась последняя нода - она просто становится корнем всего дерева.
Получится примерно следующее:
Кодирование Хаффмана было изобретено очень давно, но используется до сих пор в алгоритмах кодирования.